Kube-#01.2 Docker镜像的原理
- MetricVoid
- 8月 7, 2021
- 技术笔记
- 0 Comments
一个Docker镜像从外部来看,是一个文件系统:里面包含着各种操作系统的文件、语言运行时的文件、应用程序文件等。但是事实上,一个docker镜像是由许多层组成的。
- 每一”层“和一个git commit差不多。每一层在上一层的基础上,只能增加和覆盖文件。删除文件只能让文件看不到,但它还是存在的,不会减少镜像大小,因为这一层无法更改上一层的内容。
- 随着层数增加,镜像大小只会增加不会减小,因为每一层不可能拥有负的大小。
- 每一层有一个十六进制的ID,和git commit hash类似。
- 镜像在本地和Container Registry中是按照层存储的。每一层按照他们的ID来索引。镜像的名字表示了一个配置文件,存储了一系列层的信息。最顶层就是我们看到的镜像。
使用dive调查一个镜像
有一个叫做dive的工具,可以用来查看docker镜像的层数,可以在这里找到它 -> GitHub – wagoodman/dive: A tool for exploring each layer in a docker image
让我们用这个工具来调查一下python:3.9.6-alpine这个镜像。
注:docker inspect 也可以用来查看镜像,但是没有dive好用。
dive python:3.9.6-alpine
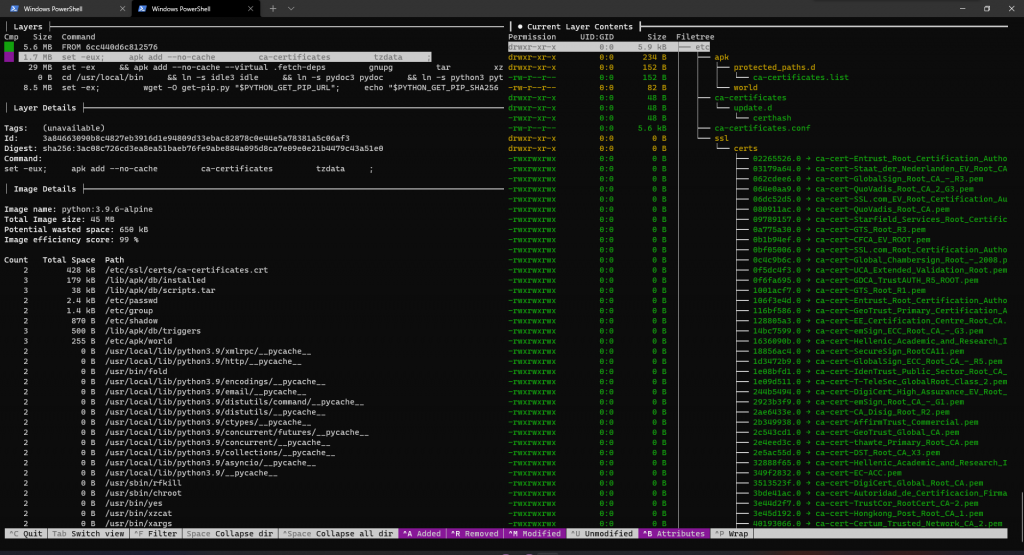
屏幕下方显示了键位操作。TAB键可以在检视层和检视当层文件之间切换。在检视文件时,用Ctrl+A/R/M/U/B可以显示/隐藏文件(比如现在隐藏了“未更改”的文件,只显示每层修改的内容)。左边的Layer Details显示了当前层的大小和ID,Image Details显示了镜像名以及大小。左下角显示的是镜像中可能冗余的文件,我们现在不用管。
可以看到,这个镜像一共有五层,每一层都执行了一些命令,向这个镜像中添加了新的文件,包括安装时区数据,安装python,配置pip等。最终到我们手上的镜像就是一个配置好了运行环境,开箱即用的python。
可以再在这个地方多转转,看看每一层是怎么设计的。
分层的优点
层共享
镜像分层带来的一个优点就是 – 层可以共享。
比如我构建了两个python程序,都基于python运行。这两个镜像除了最顶端我自己写的部分以外,底下的Python运行时是一样的。也就是说,无论是在存储的时候还是在运行的时候,这个共同的部分只需要被保存和加载一次。这大大节省了本地的空间。例如,python安装完numpy, pandas和scipy之后,镜像大小逼近500M,但是之后写的基于这些依赖库的程序,在存储和运行的时候都可以共享同一个运行时。
生命周期管理以及资源的节省
在运行一个镜像的时候,Docker相当于在这个镜像上添加了一个新的层 – 这个层对你的应用程序来说是可写的,你的应用程序对于本地文件的所有操作都会体现在这个层里,而镜像中的所有层对于应用来说是只读的。在这个容器结束时,这个临时的可写层也被删除。
这也就是说,运行的镜像所占用的额外硬盘空间仅仅是最上面那一层可写层,运行相同应用的多个实例时,既不需要把下层全部复制一遍,又保证了不同实例之间的独立性。销毁实例也变得非常简单。
层是怎么来的
在构建镜像时,有一些指令不会创建层,有一些指令会创建新的层。分层并不是自己定义的,而是构建镜像过程中自然生成的。下一篇讲解构建docker镜像。
